Every major cloud provider now ships an agent story: AWS AgentCore, Google Vertex AI Agents, OpenAI's enterprise push. The pitch is the same in each case. Spin up a model, point it at your documents, add a chat interface, and you have a deployed agent.
In practice the deployment falls short where it matters. When a maintenance technician at a valve plant, or a salesperson at an industrial distributor, asks which seat material is compatible with a chlorine-based fluid at 180°C, the system answers fluently and gets it wrong.
The state of industrial AI in 2026 comes down to one observation: the models are good enough, and the architecture around them is not.
Most agent deployments are built on an implicit assumption, that intelligence is the bottleneck. So teams chase better models, bigger context windows, fancier retrieval pipelines. RAG over PDFs, web search over public documentation, embeddings on everything. Yes, but the technician still gets a wrong answer, because the real bottleneck was never the model. It was the gap between what the model was given and what it actually needed to know.
We learned this the hard way. Our first agents at ReshapeX were built in Langflow: nodes, long prompts, consume MCP tools to perform RAG. They hedged on questions they should have answered precisely, and answered precisely on questions they should have hedged. Not because the model was bad, because the harness was wrong.
This post describes what we rebuilt and why. It is a case study in what industrial AI requires when the domain is specific, the data is private, and a wrong answer is worse than no answer.
Where we started: the Langflow era
When AI agents began gaining traction, most companies bet on platforms that already let them build automation quickly. Langflow was one of them: an open-source visual editor where you wire LLMs, tools, and retrieval steps onto a canvas as nodes, each one a Python component you can customize. Under the hood it ran on LangChain 0.3, the "classic" version, which organized computation into Chains, predetermined steps such as "retrieve, then generate." Langflow converted those steps into its own component system and added a self-built graph execution engine on top.
We built on it throughout 2025. It let the team move fast: connect a knowledge base, add RAG over PDFs, wire in third-party tools, and deploy a working agent in days. For document ingestion, Langflow ships with built-in nodes that parse PDFs into text using PyPDF. We later built custom components on top of that, integrating LlamaParse, a SaaS parsing service, to get better structured extraction from dense industrial documents. We also built custom components for hardcoded product configurators: agents invoked these components to walk through configuration logic and produce specialized SKUs. The approach worked, but it was fragile. Every time a product line changed or a single configuration rule was updated, the code had to change to stay in sync. At a handful of products that is manageable. Across a growing catalog it becomes a maintenance problem that does not scale.
For a while, things improved incrementally. Better parsing gave us cleaner input. Tighter prompts narrowed the drift. But two deeper problems kept surfacing, and neither had a fix inside the platform.

Vector search doesn't understand relationships
Our customers' knowledge lives inside product catalogs, spec sheets, ERP records, and years of accumulated documentation. Almost none of it is flat. A part belongs to a product family. A component cross-references a competitor equivalent. One spec sheet constrains the interpretation of three others.
Standard RAG treats this as a text retrieval problem: embed everything, find the closest chunks, pass them to the model. The limitation is that vector similarity finds semantically close text, not structurally connected information. When a technician asks whether a valve seat material is compatible with a specific fluid at a given temperature, the answer may require connecting a material property, a chemical compatibility table, and an operating range spec that live in separate documents with no shared vocabulary. Vector search surfaces each chunk in isolation, and the relationships between them never reach the retrieval layer. They land on the model as raw fragments to piece together.
The obvious workaround is to skip retrieval and just shove whole documents into the context window. We looked at it, but it hits three hard walls. First, most provider APIs cap token limits, which makes full-document ingestion impractical once a catalog reaches any real size. Second, sending thousands of tokens per query across a lot of concurrent users gets expensive fast. Third, and less obvious, bigger context doesn't buy you proportionally better answers. Databricks tested this across 13 models and found that for most of them accuracy peaks and then drops past a certain context size: Llama-3.1-405b starts slipping after 32k tokens, GPT-4-0125-preview after 64k, and only a handful of models hold accuracy out at long context. They also saw models fail in stranger ways as context grew, like summarizing the input instead of answering the question, or just returning a wrong answer. Past a certain point, more context makes the model worse, not better.
The result was inconsistency. The same question, phrased slightly differently, pulled different chunks and produced a different answer. Better parsing helped at the margins, but the structural problem remained: chunks without relationships are still just chunks.
Langflow's architecture had a ceiling
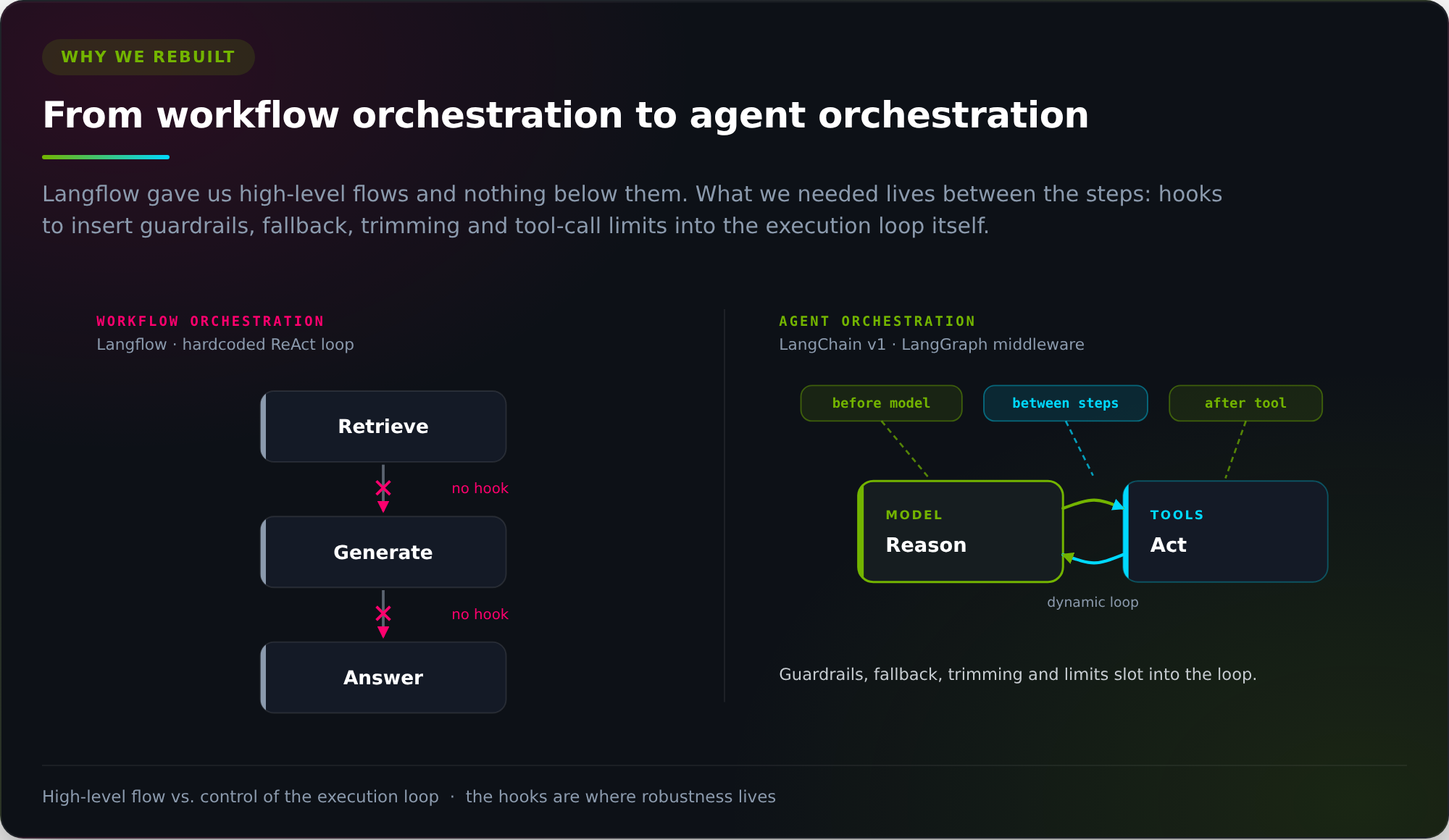
The second problem was more fundamental. Langflow is built for workflow orchestration, high-level predefined flows, and we needed agent orchestration, low-level dynamic control over the execution loop.
This distinction matters in practice. Langflow's Agent node uses its own create_agent implementation with a hardcoded ReAct loop. The only real extension point the platform exposes is custom components, which operate at the flow level. What we eventually needed (input guardrails, context trimming, fallback providers, tool-call limits) required inserting logic before a model call, after a tool call, and between reasoning steps. Those hooks do not exist in Langflow. They are abstracted away behind its execution engine.
LangChain v1, which introduced middleware as a first-class concept backed by LangGraph, provides exactly that. But the two ecosystems are not compatible migration targets. Langflow's flows are built around LangChain 0.3's chain abstractions, which LangChain has since replaced with LangGraph-backed agents. The high-level flow model and the low-level agent execution model are architecturally different, so patterns available in one have no direct equivalent in the other.
By early 2026 it was clear that both problems hit the same ceiling: Langflow gave us high-level orchestration and nothing below it. Moving to LangChain/LangGraph v1 meant rebuilding from scratch, which is what we did.
Why prompts weren't enough
An industrial buyer asks an agent: "I need the right enclosure heater for a 30°C ambient, 1.2m³ cabinet, NEMA 4X." A wrong answer here is not merely embarrassing. It becomes a returned shipment, a tripped breaker, or a salesperson's afternoon spent unwinding a bad quote. Consumer chat tolerates "close enough." but Industrial commerce does not. Every answer has to be grounded and traceable to a real part, a real specification, and a real source.
That single requirement proved harder than it first appeared. In pursuing it we ran into a set of recurring problems, and a set of recurring opportunities, that no amount of prompt-tuning could resolve. What follows is an account of those challenges and why each one mattered.
Finding the needle in the haystack
Our customers are manufacturers and distributors sitting on large, unstructured bodies of knowledge: product catalogs, specification sheets, CAD files, ERP records, and years of tribal expertise. Almost none of it is organized for a machine to retrieve. The information exists, but it is scattered, inconsistent, and difficult to access on demand.
The deeper problem is that the relationships between pieces of information matter as much as the information itself. A part is compatible with another part. A product belongs to a family. One component cross-references a competitor's equivalent. Answering an industrial question correctly often means navigating this web of connections, not just locating a single document. Surfacing the one right answer out of millions of near-identical candidates, while understanding how that answer relates to everything around it, is the central difficulty of the system.

When you need an exact match, similarity works against you
A buyer types a part number like FVAM-2050-B and expects the agent to find exactly that. Vector search does not look for exact matches. It looks for similar things, and FVAM-2050-B and FVAM-2050-C sit close together in embedding space while being completely different parts. The agent surfaces five plausible results, picks the most confident-sounding one, quotes it, and the wrong part ships.
The fix is to give retrieval a mode switch. A knowledge base client is the agent's librarian: it searches your private documents and hands back the relevant pieces so the agent can answer from your actual data. Our KB client exposes an alpha parameter that blends two search strategies, pure vector similarity at one end and pure keyword (BM25) match at the other. For part-number lookups we dial alpha down to 0.15, so keyword match does the heavy lifting and vector similarity only breaks ties. We also add a pre-filter that restricts the search to documents where the item_id field matches the query token before scoring starts, so the model never sees the near-misses.
if match_search == "exact":
metadata_filter = json.dumps({"item_id": [item_id.strip()]})
await retrieve.ainvoke({
"alpha": 0.15, # keyword-dominant: exact tokens beat semantic proximity
"strict_keyword_match": True,
"metadata_filter": metadata_filter,
})General questions still use the default alpha=0.55, which stays balanced. The agent does not choose the mode; the tool definition hard-codes the right one for the query type.
When the answer lives across three documents with nothing linking them
A technician asks: "Is a PTFE seat compatible with a chlorine-based fluid at 180°C?" The correct answer requires connecting three separate facts: a material property sheet (PTFE temperature ceiling), a chemical compatibility table (PTFE versus chlorine), and an operating range spec for the valve series. These live in three different documents, written by three different engineers, with no shared vocabulary.
Standard RAG treats this as three independent lookups. Each chunk comes back in isolation, the model sees fragments with no edges between them, and it synthesizes the best answer it can from disconnected pieces. It gets the compatibility wrong.
The fix is a knowledge graph. Our GraphRAG client does not just retrieve chunks, it traverses the relationships between them. The default hierarchical strategy fuses vector search, full-text search, and graph traversal in a single pass using Reciprocal Rank Fusion. Once a candidate entity is surfaced, a follow-up get_entity_chunks call drills into that node's connected documents directly, navigating the relationship rather than re-running retrieval from scratch.
async def search_graphrag(
query: str,
strategy: Literal[
"hierarchical", # vector + full-text + graph traversal fused via RRF
"neighborhood", # seed from closest vector match, walk 1-hop graph edges
"text2cypher", # LLM writes a Cypher query against the graph schema
"global", # broad sweep for high-level, domain-wide questions
] = "hierarchical",
) -> dict: ...The technician's question now resolves to a path through the graph, from a material node along a chemical compatibility edge to an operating range node, instead of three isolated chunks.
Keeping Context manageable
A serious industrial conversation is long and information-dense. Each exchange may pull in large volumes of supporting material, and over the course of a dialogue that material accumulates quickly. Left unchecked, the conversation's working memory grows until it becomes unwieldy: slower, more expensive, and eventually impossible to sustain.
The opportunity was to treat context as a finite resource to be managed deliberately, rather than something that fills up until it fails. An agent that cannot remember what was said three turns ago is useless. An agent that tries to remember everything, in full detail, forever, is unaffordable and eventually breaks. Striking the balance between preserving what matters and discarding what does not was a problem we had to solve before the agents could hold a real conversation.
When the conversation grows faster than the context window

Configuring an industrial enclosure heater is not a one-message job. A salesperson might spend 30 messages narrowing constraints: cabinet volume, ambient temperature, IP rating, voltage, mounting type. Each exchange matters, and the voltage specified in message 5 is still a hard constraint in message 55.
The context window does not track business logic. It fills up. By turn 40 the window is nearly full, and by turn 60 the model starts ignoring early constraints, not because it forgot them but because they have been physically crowded out of the context. The model answers the question in front of it, blind to the ground it already covered.
The fix is to treat history as a resource you actively manage. At 70 messages a middleware fires and compresses the oldest 20 into a single structured summary, preserving constraints and stripping noise. Tool call and result pairs are excluded from summarization, because they are too verbose to summarize usefully and the raw content is not what matters after the fact. The 50 most recent messages stay verbatim. The model picks up the thread with everything it needs and nothing it does not.
SummarizationIgnoreToolMessagesMiddleware(trigger=70, keep=50)
# At 70 messages: compress oldest 20 → one summary block, keep newest 50 verbatim
# Tool messages excluded: too noisy to summarize, not load-bearing after the factWhen one tool result fills the entire window
A product catalog search can return a JSON dump of 200 items, potentially hundreds of thousands of characters from a single tool call. Feed that directly to the model and there is no room left for conversation history, the system prompt, or any subsequent tool calls. The model does not crash. It fixates on whatever appears in the first few thousand tokens and ignores the rest, and answer quality degrades without any visible error.
There are two layers of defense. The first is a hard cap: every tool result is intercepted before it reaches the model and truncated at 100,000 characters. The second is a recovery path: if the context still overflows despite the cap, because history has accumulated over a long session, the system catches the provider's overflow error, strips all tool history from the request, and retries once. The conversation degrades gracefully instead of failing.
# Layer 1: cap every tool result before it reaches the model
class ToolOutputTrimmerMiddleware: # runs after tool execution
async def awrap_tool_call(self, call, next):
result = await next(call)
return result[:100_000] # hard ceiling regardless of tool type
# Layer 2: if overflow still happens, strip history and retry once
class ContextOverflowCleanupMiddleware: # runs around the model call
async def awrap_model_call(self, request, next):
try:
return await next(request)
except ContextLengthExceededError:
request = strip_tool_history(request)
return await next(request) # one clean retryKeeping the agent aligned across many capabilities
A capable industrial agent needs to do many things. It searches knowledge, drives product configurators, looks up live inventory, captures leads, and more. But capability and focus pull against each other. The more an agent can do, the easier it is for it to lose the thread, wander off its purpose, mishandle a task, or apply the wrong capability to the wrong question.
The challenge was orchestration: guiding an agent through a wide range of skills and tools while keeping it aligned with its goal and the scope it was given. An agent should know not only how to do something, but whether it should, and it should stay on-mission across a long, branching interaction. Maintaining that discipline as the number of capabilities grew was a constant pressure.

When the model can't stop calling the same tool
A proximity-sensor manufacturer agent called search_kb, got a result that did not include the exact spec it needed, and called search_kb again with a slightly rephrased query. Then again, fifteen times in total. Each call returned near-identical chunks, the context filled with retrieval noise, and the eventual answer was no better than what the first call would have produced.
The prompt instructed the model not to loop, and the model looped regardless. A prompt can set intent, but it cannot enforce it.
The fix lives one layer below the prompt. ToolHardLimitMiddleware runs before every model call and counts how many times each tool has been invoked in the current turn. Once a tool hits its limit, it disappears from the list the model receives, and the model cannot select a tool it cannot see. The loop becomes structurally impossible rather than a matter of instruction.
class ToolHardLimitMiddleware:
per_tool_limit: int = 3
always_on: set[str] = {"search_kb"} # some tools are never removed
async def awrap_model_call(self, request, next):
counts = self._count_current_turn(request.messages)
# Works across both OpenAI and Anthropic tool call formats
request = request.with_tools([
t for t in request.tools
if t.name in self.always_on or counts.get(t.name, 0) < self.per_tool_limit
])
return await next(request)When more capabilities mean more ways to go off-script
An agent built for technical pre-sales, spec lookups, compatibility checks, and product selection also had a lead-capture tool. A technician asking "what's the maximum switching frequency for a BIM-UNT-AP6X?" occasionally triggered the lead-capture flow mid-answer. The model had internalized lead capture as a high-value action and applied it too eagerly. The more tools an agent has, the more surface area there is for the wrong one to fire at the wrong moment.
The fix is not a smarter prompt but a fixed execution contract. Every agent runs a middleware stack where each hook fires at a specific moment, before the agent, around the model call, and after the agent, and the order is defined in code. LeadCaptureIntentMiddleware runs as an aafter_agent hook: it fires only after the main answer is delivered, and only if a lightweight intent classifier scanning the last 8 non-tool messages detects genuine purchase intent. The technician's spec question gets answered, and lead capture stays quiet, because the architecture sequences them that way.
# Each middleware fires at a specific lifecycle hook, order is fixed, not negotiable
middlewares = [
NoAssistantPrefillMiddleware(), # runs before everything (Claude compat)
LoggingModelFallbackMiddleware([openai_model]),# wraps the model call
SafetyGuardrailMiddleware(threshold=0.5), # before_agent: can stop early
ToolHardLimitMiddleware(per_tool_limit=3), # before model call: caps tool access
ToolOutputTrimmerMiddleware(), # after tool: caps result size
ToolCallLimitMiddleware(run_limit=30), # hard ceiling for the whole turn
SummarizationIgnoreToolMessagesMiddleware(), # before_agent: compresses history
ContextOverflowCleanupMiddleware(), # around model call: overflow recovery
LeadCaptureIntentMiddleware(context_window=8), # after_agent: fires last
SafetyOutputGuardrailMiddleware(), # after_agent: screens output
StripToolHistoryMiddleware(), # after_agent: cleanup
]Ensuring nothing unsafe gets in
Every conversation opens with a risk at the input. Users may try to manipulate the agent, jailbreak it, extract its instructions, or push it outside its intended purpose.
A manipulated agent is a liability, and an agent that exposes its own internals looks broken and untrustworthy. Treating incoming requests as things that must be checked, rather than trusted by default, was essential to making the system safe to put in front of real customers.

When a blocked message tells you nothing
An early deployment used a binary safe/unsafe classifier: pass or block. It caught obvious jailbreaks, but it also blocked a buyer asking about a competitor's equivalent part, and a technician writing in German the classifier had not been trained on. Every rejection looked identical in the logs, a zero. There was no way to tell "clearly trying to extract the system prompt" from "out of scope but completely harmless," and no way to tune the threshold without guessing, because guessing was all the data allowed.
A score without reasoning carries no signal. What makes a guardrail useful in production is not that it blocks things, it is that it reports why it blocked them, consistently enough that you can improve.
Our guardrail returns a structured response with two fields, rationale and score. The field order matters: rationale comes first in the schema, so the model has to articulate its concern before it assigns a number. In practice, messages that would snap-judge to 0.7 often resolve to 0.4 once the reasoning is written out. The block threshold is a number you configure per deployment, so a strict customer-facing agent and a permissive internal tool share the same guardrail logic with different thresholds.
class SafetyGuardrailResponse(BaseModel):
rationale: str # produced first, forces reasoning before scoring
score: float # 0.0 (unsafe) → 1.0 (safe)
# score=0.15, rationale="probing for system prompt via indirect instruction" → block
# score=0.82, rationale="competitor part question, not adversarial" → redirect insteadIntegrating deeply with the customer's own systems
A grounded answer is frequently not a paragraph of text at all. It is an action taken inside the customer's existing stack: configuring a product, recording a sales lead, sending an email. Each of these requires the agent to reach into the customer's own software and operate it on their behalf.
This created two distinct opportunities. The first was using the customer's product configurators as interactive elements within the conversation, so a buyer could work through a real configuration rather than read a flat description of one. The second was connecting to the systems that run the customer's business, their CRM, email, commerce, and inventory platforms, so the agent could create leads, send messages, and act on live data instead of talking about it. Both required deep integration with software we did not build and could not change, which is markedly harder than answering questions in isolation.
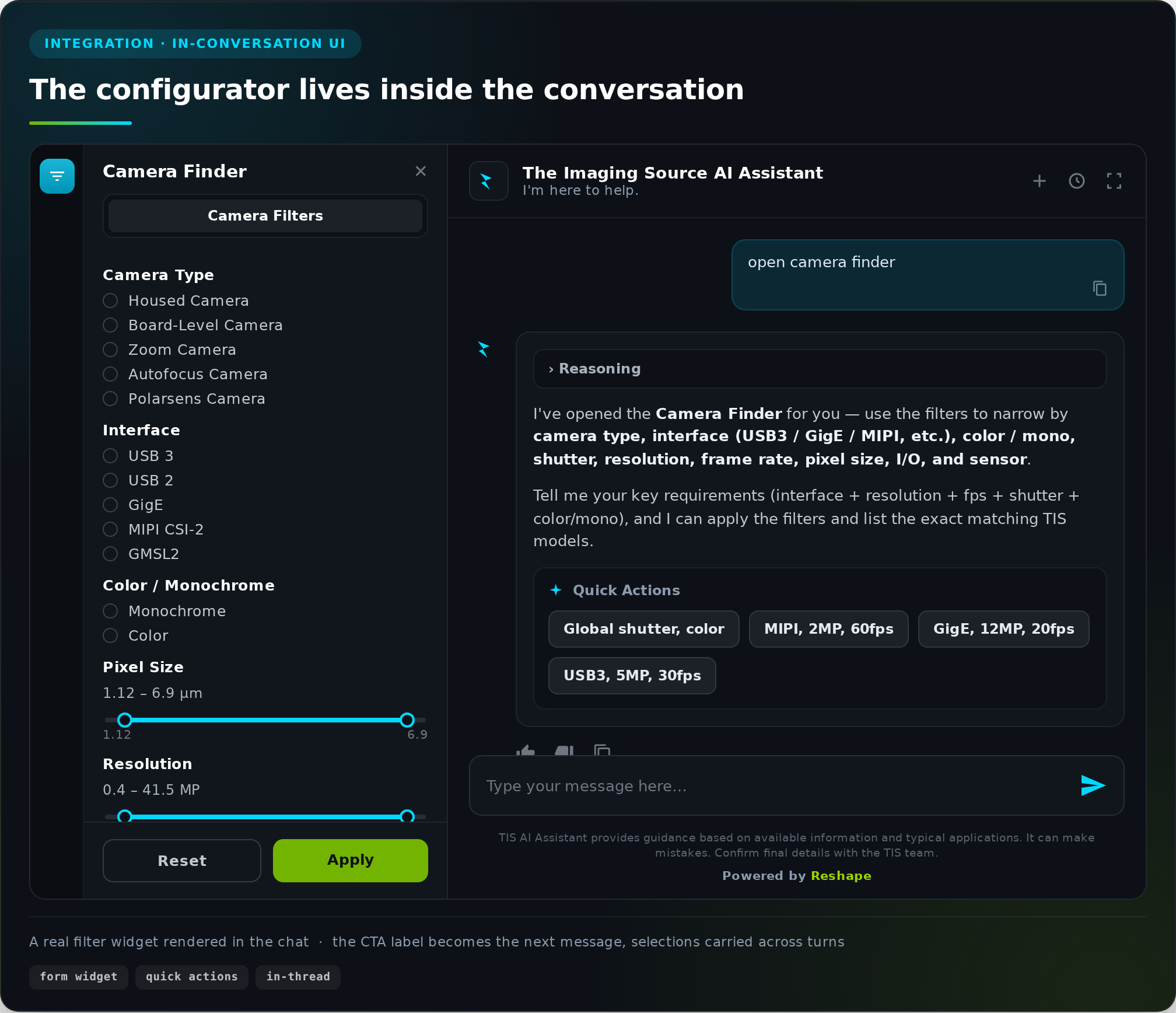
When the configurator lives somewhere else
Early on, the agent described a product configuration flow in text: "you can configure this valve by specifying shaft diameter, seal material, and actuation type." The buyer read that, left the conversation, went to the manufacturer's website, configured the part there, and maybe came back with a follow-up question. The agent had no memory of what they had chosen. The conversation and the actual configuration lived in separate places, two threads that never talked to each other.
The fix was to bring the configurator inside the conversation. The agent now builds a form widget directly from the manufacturer's API specList, with real fields and real options, reflecting whatever the buyer has already selected in prior turns. When the buyer clicks a CTA button, that button's label becomes their next message. "I want to configure the LB series" arrives as plain text, the model reads it, continues the conversation, and the next form renders with their selection already applied. No redirect, no separate tab. The configuration and the dialogue are the same thread.
# CTA label becomes the next user message, no custom JS needed
CatalogDistributorProductWidget.from_series_list(series_list)
# → cta_instruction="I want to configure the {code} series."
# Form reflects prior selections across turns
def _build_spec_form(spec_list, applied_specs: dict) -> FormWidget:
for spec in spec_list:
selected = applied_specs.get(spec["specCode"]) # carried from conversation state
fields.append(TextInputField(spec, selected=selected)
if spec.get("unit") else DropdownField(spec, selected=selected))
return FormWidget(fields=fields)When the action happens outside the conversation
A salesperson agent could identify the right enclosure heater, confirm pricing, check availability, and then stop. To send the quote, the salesperson had to copy the answer out of chat and open their email client. The agent did the thinking and the human did the executing, and every hand-off is a chance for information to drift: a wrong number transcribed, a spec dropped, a detail lost between the chat window and the compose window.
The gmail_send_email tool connects to the customer's own Gmail account through per-customer OAuth, managed by Composio. The model decides when to call it, after it has confirmed the buyer's intent and settled the quote details. The salesperson does not leave the chat, the agent sends the email, and it confirms the send in its next message. The decision and the action happen in the same place.
@tool
async def gmail_send_email(recipient_email: str, subject: str, body: str) -> dict:
client = Composio(api_key=settings.composio_api_key)
return client.tools.execute(
slug="GMAIL_SEND_EMAIL",
arguments={"recipient_email": recipient_email, "subject": subject, "body": body},
connected_account_id=settings.composio_account_id, # per-customer OAuth token
)
# The model calls this when it decides the moment is right, not on every lead,
# not on every product recommendation, only when the conversation has reached a
# point where sending makes sense.Seeing what is actually happening
An agent deployed into the world is only as useful as our ability to observe it. Without visibility there is no way to know whether it is helping or hurting, where it succeeds, and where it quietly fails.
The opportunity was to capture the signals that reveal real performance: where users engage from, how the agent is used, and, most valuable of all, direct feedback on whether a given answer was good. These signals close the loop between deployment and improvement. They turn each conversation from a one-off interaction into evidence that makes the next one better. Building the means to gather them, without interfering with the experience itself, was the final piece of the problem.
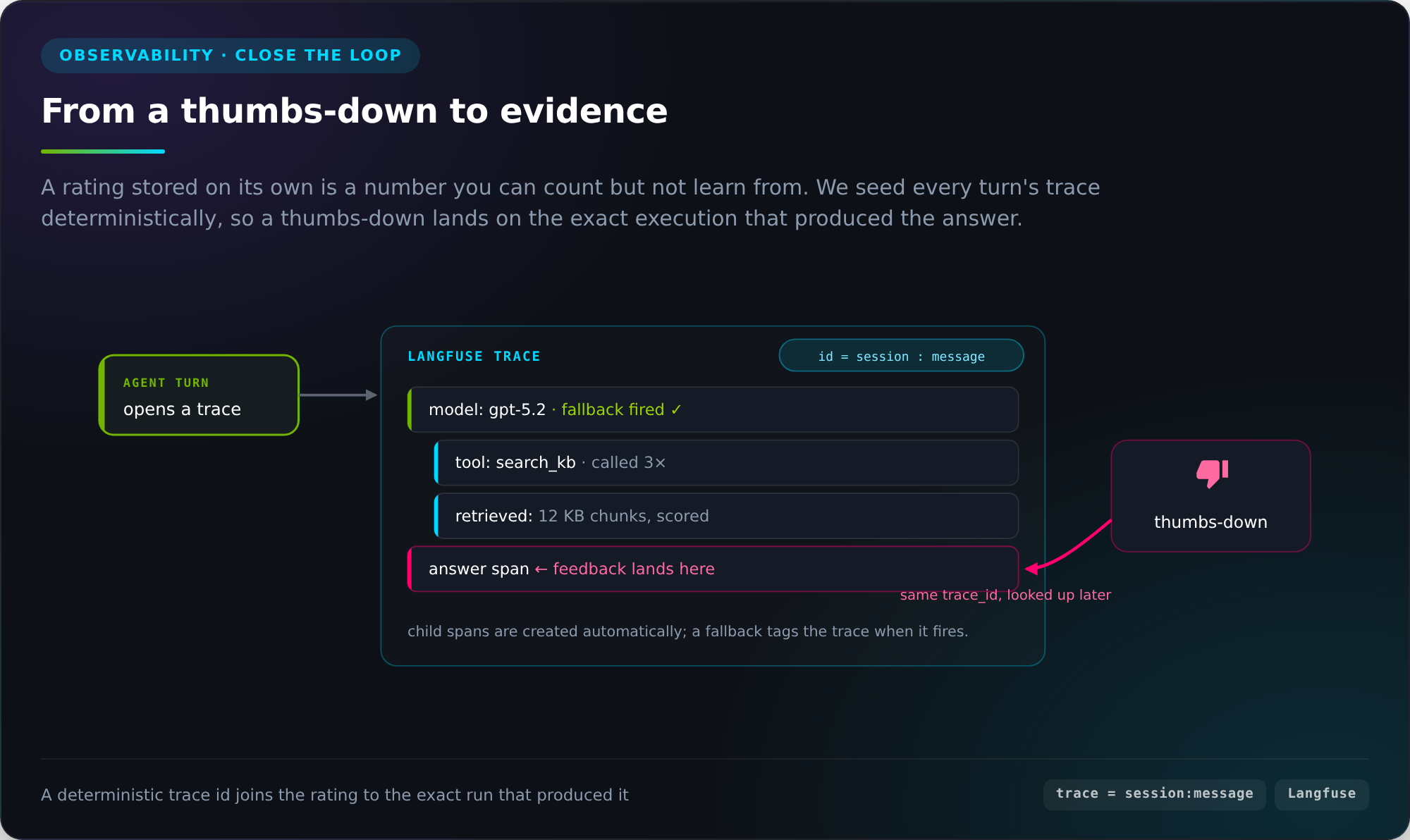
When a thumbs-down carries no context
An early deployment collected feedback, thumbs up and thumbs down, and stored it as isolated records: a score, a timestamp, a session ID. When a buyer marked an answer as wrong, there was no way to connect that signal to anything useful. Which model answered? Which tools did it call? What did it retrieve? Did a provider fallback fire mid-turn? The feedback existed, and the evidence that would let you act on it did not. A thumbs-down with no context is a data point you can count but not learn from.
Every agent turn now opens a Langfuse trace with an ID seeded deterministically from session_id:message_id. The same message always maps to the same trace, no matter when the feedback arrives. When a buyer submits a rating, the feedback endpoint looks up the trace ID stored against that message and posts the score directly to the span that produced the answer. The feedback and the execution record are joined.
In practice, a thumbs-down on a proximity-sensor manufacturer sensor recommendation opens a trace that shows exactly which model answered, whether a provider fallback fired mid-turn, which KB chunks were retrieved, and how many times search_kb was called before the answer landed. The signal becomes evidence, and each conversation stops being a one-off interaction and starts making the next one better.
# Deterministic: same session+message → same trace, always
trace_id = langfuse.create_trace_id(seed=f"{session_id}:{message_id}")
with langfuse.start_as_current_span("agent_turn", trace_id=trace_id):
# Tool calls create child spans automatically
# Provider fallbacks tag the trace when they fire
result = await run_agent(...)
# POST /messages/{id}/feedback, joins rating to the exact span
agent_trace_id = human_message.additional_kwargs.get("agent_trace_id")
scores = "positive" if req.properties.feedback else "negative"
langfuse.score(trace_id=agent_trace_id, name="user_feedback", value=score)These six challenges share a single lesson. None of them could be solved by writing a cleverer prompt or choosing a better model. Each was a question of how the surrounding system is built: how information is organized, how memory is managed, how capability is governed, how safety is enforced, how integrations are wired, and how the whole thing is observed. That is why we rebuilt our industrial AI agents from the ground up, and why we believe the same holds in general. The harness is the architecture.
Why general LLMs aren't enough? Context engineering: the harness's first discipline
When customers started asking our agents questions like "does this part fit my machine?" or "what's the right cable for this connector?", we ran into a wall that better prompting could not fix.
The wall is not the model's capability. It is what the model knows at the moment it has to answer.
A general-purpose language model has no access to a manufacturer's private product catalog, no awareness of which items are in a distributor's inventory, no memory of what the customer said three messages ago, and no understanding of which constraints have already been established in the conversation. It reasons well over information it has. The problem is that for industrial sales, most of the relevant information does not exist in the model's training data. It exists in private APIs, live inventory systems, and the customer's own session.
This is the core problem: the model is capable but has no access to what it needs.
Making it useful requires solving a different problem than capability. It requires deciding, for every model call, what information goes into the context window, in what form, at what granularity, and what gets left out.
That discipline is what we call context engineering. The term has gained traction recently, and it maps to something we kept rediscovering in our own work: the limiting factor for agent quality is not which model you use, it is how much of the right information the model can see at inference time.
Context engineering is not only about adding information. It is also about removing it.
Long-running sessions accumulate tool calls, retrieval results, and intermediate reasoning steps that quickly exhaust the context window. Part of the system's job is deciding what no longer matters: trimming execution traces, compressing history, and preserving just enough thread for the model to stay coherent.
The challenge is not maximizing context. It is maximizing useful context.
In practice, context engineering spans five overlapping concerns.
Prompt engineering
Prompt engineering shapes the model's base behavior: its role, its reasoning strategy, and its constraints. The problem it solves is the blank-slate model. Without deliberate instruction, a capable model still gives generic answers.
Retrieval-Augmented Generation (RAG)
RAG grounds the model in private, live data. When a customer asks about a product, we pull from manufacturer APIs and a hybrid-search knowledge base built from curated technical documentation. The model does not hallucinate catalog specs; it reasons over retrieved data it can cite.
State and history
State and history prevent the conversation from resetting on every turn. A customer might spend ten messages narrowing down a product, specifying voltage, form factor, mounting type, and available cabinet space. Each of those constraints is context that every subsequent model call needs. Without explicit state management, each answer ignores everything that came before.
Memory
Memory extends that across sessions. A returning customer should not have to re-explain their machine configuration from scratch. Session checkpoints persist the conversation graph so the agent resumes with full context rather than a blank slate.
Structured output
Structured outputs make the agent's responses composable with downstream systems. When the model returns a product recommendation or a compatibility judgment, it returns a typed object, not prose another system has to parse and trust. This is what lets agent responses trigger UI components, update configuration state, or feed into the next tool call reliably.
In practice this often looks like a middleware stack running before every model invocation. Some components inject context: the agent's current configuration state, the active workflow, or the tools relevant to the task at hand. Others remove information that no longer contributes to the answer. By the time a prompt reaches the model, the context has already been curated, filtered, and structured for the reasoning step that follows.

These five concerns overlap. Retrieval informs prompt composition. State shapes what is worth retrieving. Memory determines which state is still relevant. Structured outputs make state updates trustworthy.
Context engineering is one part of the harness, the part that decides what the model sees. Grounding, tool governance, safety, robustness, and observability are the rest, and the sections that follow build them out. The model at the center of all this is a commodity. The harness around it is not.
Degrading Gracefully: Fallbacks, Limits, and Runtime
A capable model is not the same thing as a reliable agent. In a demo, a single model that reasons well and calls tools is enough. In production, where an agent recommends a part a customer will actually buy, the bar is different. A wrong answer is worse than no answer, because a confidently stated but incorrect spec erodes trust faster than an honest "I don't have that." Robustness, for us, is not an uptime SLA. It is the property that the agent's output stays correct even when the things underneath it, the model, the provider serving it, and the runtime it lives in, fail or degrade. Setting the model's intent through context engineering, the subject of the previous section, is necessary but not sufficient. What follows is what we built for the moments when intent alone does not hold.

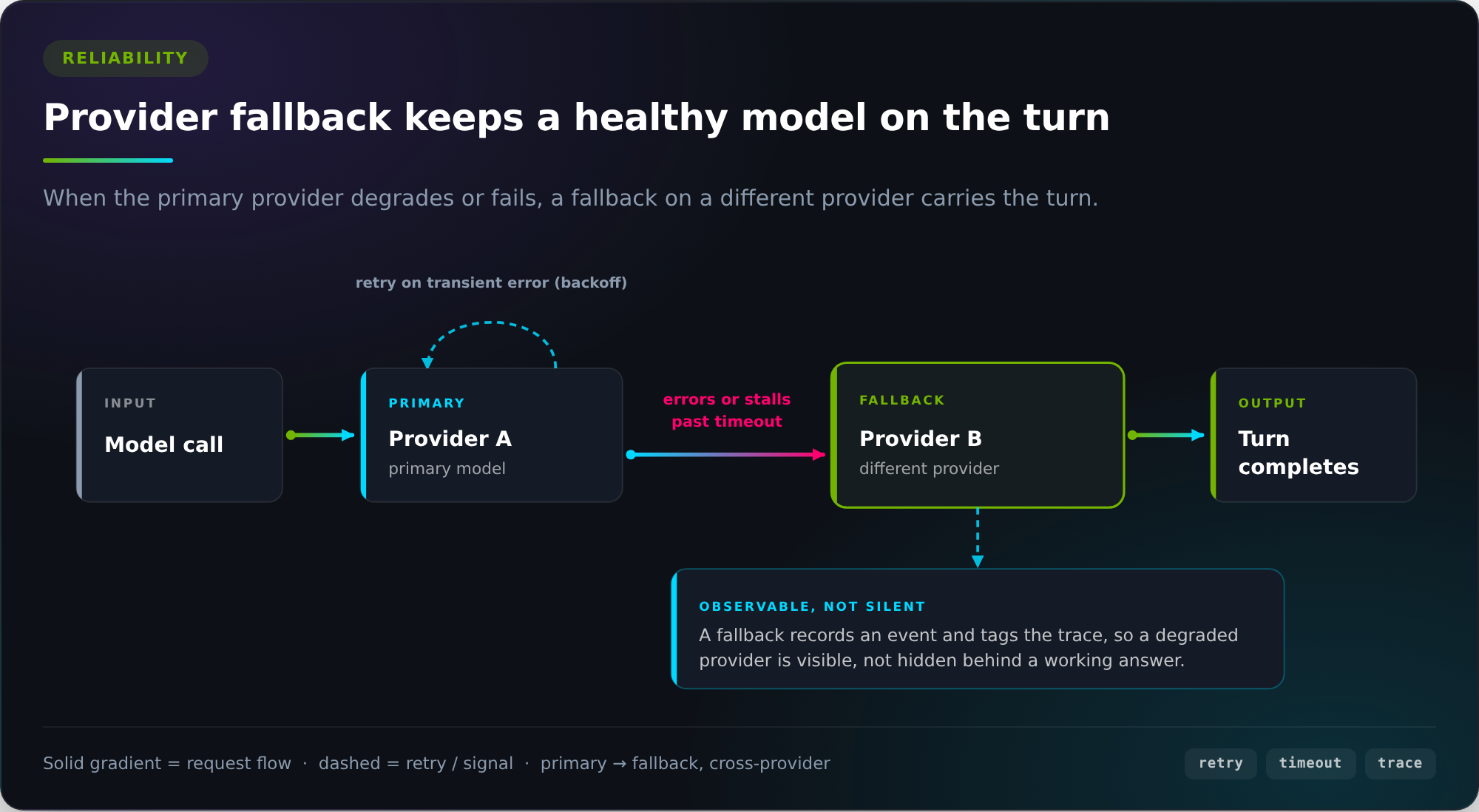
The most direct version of this problem is the model provider itself. We run agents on Anthropic and OpenAI models, and both, like any hosted service, have bad days. A provider can return errors, or it can stay up while slowing to a crawl. We have seen a provider keep answering while every call took far longer than usual, which for an agent that makes several model calls per turn is barely distinguishable from being down. An agent bound to a single provider inherits that provider's worst moment, and the customer feels it as a dead conversation. So no agent depends on one provider. Each is configured with a primary model and a fallback on a different provider, and when the primary errors or stalls past an explicit timeout, the platform fails over to the healthy one and the turn completes. Transient errors like rate limits and dropped connections are retried with backoff before any failover, and we disable the providers' own silent retries so this policy lives in our platform rather than in a vendor SDK. A fallback is never silent: when it fires, the platform records the event and tags the trace, so a degraded provider becomes something we can see rather than something hidden behind a working answer.
A subtler failure is the model that is up, fast, and still wrong about how to behave. Even with a careful prompt, a model breaks in operational ways: it calls the same tool over and over, convinced the next call will finally return what it wants, or it drowns in a tool response so large that it loses the thread. A prompt can ask it not to; it cannot stop it. We handle this one layer below the prompt, in middleware that wraps each model and tool call. One component bounds how many times a given tool may be called in a turn and takes that tool off the table once the limit is reached, ending the loop. Another caps the size of any single tool output before it reaches the model, so an oversized result is trimmed instead of crowding out everything else in the context. The model still does the reasoning; the middleware keeps the conditions it reasons under sane.
Robustness is also a question of where the agent runs. Our agents used to run on AWS App Runner, which assumes a web request is short: when an agent went quiet to reason for a while, App Runner could read the idle connection as a finished process and close it before the answer came back. We moved to AWS Bedrock AgentCore, a runtime meant for long-running agents, where a turn that spends time thinking is expected rather than terminated. Each agent gets its own runtime, built from pinned dependencies and locally built wheels behind a committed lockfile, so the exact same packages run in development and in production and a deploy cannot quietly drift between the two. Conversation state is treated the same way: in production it is checkpointed to a durable store, and the system fails loud, refusing to start if that store is misconfigured rather than silently falling back to in-memory state the customer would later lose.
Fallbacks, middleware, and infrastructure are the robustness mechanisms this section is about, but they are not all of it. The rest is developed where its problem first appears: guardrails screen what comes in and what goes out, persistent memory keeps a long, information-dense conversation coherent and lets a returning customer resume instead of starting over, and the observability that records a fallback or a poor answer is what turns a single failure into a fix. What ties them together is that none of them depends on which model happens to be underneath. The result is not a smarter agent but a more accountable one: when the easy path fails, the answer degrades into a correct, narrower response instead of a confident wrong one, which in an industrial setting is the only kind of robustness that counts.
Final Words
Every failure in this post was a context failure, not a model failure. Vector search returned chunks stripped of their relationships. Too much context made answers worse, not better. A capable model still looped on a tool, or carried a confident but wrong spec all the way to the customer. The limit was rarely the model. It was everything around it.
That "everything around it" is the harness: the loop the model runs in, and the hooks that ground it, curate its context, govern its tools, fail over when a provider drops, and keep it observable. The model is a commodity you rent. The harness is what we engineer, and it is where reliability lives. The architecture is the harness, and harness engineering is how you build it.
The biggest opportunity we see is in the harness itself. Today it reconstructs the relationships between facts on every turn, inferring them at inference time, which is implicit, approximate, and rarely the same twice. Those relationships could instead be established deliberately and up front, more deterministic, more complete, more exact, then held in a durable knowledge graph of entities, the relationships between them, and the lineage of each fact. A harness that navigates that graph instead of re-deriving it under time pressure on every call is a different kind of system, and the direction we are building toward.
The claim we are confident in today is narrower, and it holds: in industrial AI, the model is rarely the bottleneck. The harness is, and we are still finding out how far it can go. The next post goes deep on the system we are building to get there, the Knowledge Construction System that turns that graph from an idea into infrastructure.